Tutorial: OpenCL SGEMM tuning for Kepler
Note: the complete source-code is available at GitHub.Note2: a tuned OpenCL BLAS library based on this tutorial is now available at GitHub.
Note3: a WebGL2 demo of this tutorial is available at: https://www.ibiblio.org/e-notes/webgl/gpu/mul/sgemm.htm.
Kernel 8: CUDA and Kepler-specific optimisations
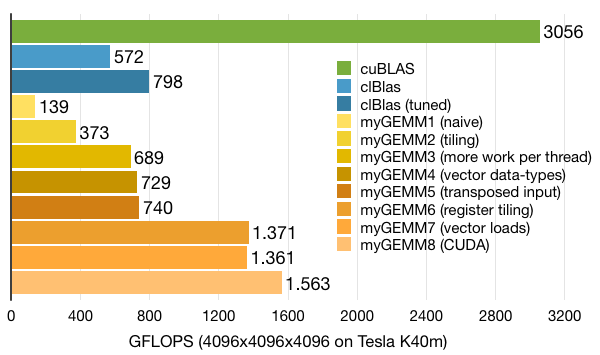
Although we are a lot faster than clBlas, we are still more than twice as slow as cuBLAS. Is this simply because our choice for OpenCL rather than the superior (?) CUDA? Let's find out!There are definitely some things that you can do in CUDA that you cannot do with OpenCL. But for starters, let's see what the exact same kernel would do if it were CUDA. To do so, we constructed a crude but functional (at least for our kernels) conversion of OpenCL kernel code to CUDA. This can simply be included as a header file just before including the OpenCL kernel code:
// Replace the OpenCL keywords with CUDA equivalent
#define __kernel __placeholder__
#define __global
#define __placeholder__ __global__
#define __local __shared__
// Replace OpenCL synchronisation with CUDA synchronisation
#define barrier(x) __syncthreads()
// Replace the OpenCL get_xxx_ID with CUDA equivalents
__device__ int get_local_id(int x) {
return (x == 0) ? threadIdx.x : threadIdx.y;
}
__device__ int get_group_id(int x) {
return (x == 0) ? blockIdx.x : blockIdx.y;
}
__device__ int get_global_id(int x) {
return (x == 0) ? blockIdx.x*blockDim.x + threadIdx.x :
blockIdx.y*blockDim.y + threadIdx.y;
}
// Add the float8 data-type which is not available natively under CUDA
typedef struct { float s0; float s1; float s2; float s3;
float s4; float s5; float s6; float s7; } float8;
Running the same kernel code through the CUDA toolchain increases performance from 1338 to 1467 GFLOPS. There are a couple of differences:
- Although both paths (CUDA and OpenCL) use the same PTX to binary assembler, they use a different front-end compiler.
- The CUDA toolchain (version 6.5) supports targeting the SM 3.5 architecture and the PTX 4.1 ISA, whereas the OpenCL toolchain (also version 6.5) does not support the native architecture (only up to SM 3.0) and PTX 3.0 at most.
- The CUDA toolchain generates 64-bit PTX on a 64-bit host machine, whereas the OpenCL toolchain always generates 32-bit PTX. The latter is advantageous in our register-heavy case, as pointers to off-chip and local memory become twice as small. The CUDA compiler has the option to generate 32-bit PTX, but only in combination with 32-bit host code.
Now, let's see if we can improve performance further by using SM 3.5 (Kepler) specific optimisations. First of all, we replace our loads with LDG instructions (see below). By simply passing the address we want to load to the __ldg intrinsic, we enable caching into the GPU's L1 texture cache. This gives us a boost from 1467 to 1563 GFLOPS.
#ifdef USE_LDG
floatX vecA = __ldg(&A[indexA]);
floatX vecB = __ldg(&B[indexB]);
#else
floatX vecA = A[indexA];
floatX vecB = B[indexB];
#endif
Another SM 3.5 specific optimisation is to use the warp-shuffle instructions to reduce local memory operations. The __shfl intrinsic allows threads within a warp (32) to share data amongst each other without going through the local memory. This can be used for example when loading values of Bsub from the local memory into the register. In the current kernel code, each thread in the first dimension (tidm) loads a set of identical values. We can replace this by letting each of them load a single unique value and share it through warp-shuffles:
// Cache the values of Bsub in registers
#ifdef USE_SHUFFLE
int col = tidn + (tidm % WPTN)*RTSN;
float val = Bsub[k][col];
for (int wn=0; wn<WPTN; wn++) {
Breg[wn] = __shfl(val, wn, WPTN);
}
#else
for (int wn=0; wn<WPTN; wn++) {
int col = tidn + wn*RTSN;
Breg[wn] = Bsub[k][col];
}
#endif
We can do something similar when loading data from A, but is this slightly more complicated and involves the use of __shfl_up and __shfl_down. In any case, warp-shuffle instructions do not improve performance in our case. In fact, performance is slightly reduced because of the increased number of instructions.
CUDA also gives us a bit more freedom with respect to the L1 cache configuration, but going from a 48KB/16KB configuration to a 32KB/32KB configuration does not give us much extra. The same holds for setting the local memory's bank size to either 4 or 8 bytes:
cudaDeviceSetSharedMemConfig(cudaSharedMemBankSizeEightByte); cudaDeviceSetCacheConfig(cudaFuncCachePreferEqual);
Finally, we could try to generate 32-bit PTX code to save precious registers. Since this option (nvcc -m32) also generates 32-bit x86 code, it is not trivial to get this working on our test system. We leave it up to you to test.