
Tutorial: OpenCL SGEMM tuning for Kepler
Note: the complete source-code is available at GitHub.Note2: a tuned OpenCL BLAS library based on this tutorial is now available at GitHub.
Note3: a WebGL2 demo of this tutorial is available at: https://www.ibiblio.org/e-notes/webgl/gpu/mul/sgemm.htm.
Introduction
This article describes a GPU OpenCL implementation of single-precision matrix-multiplication (SGEMM) in a step-by-step approach. We'll start with the most basic version, but we'll quickly move on towards more advanced code. Each step introduces a new optimisation - and best of all - working OpenCL code. This means that you'll be able to test it and tune it for your own machine. To make it even easier for you, there is also a GitHub repository online with a benchmarking infrastructure and kernel code for each step.The first few steps of this article are rather basic, so those familiar with tiling might want to skip ahead. Nonetheless, these first steps can be very useful for those that want to learn about basic OpenCL optimisations (in general) or the design space of parallel matrix-multiplication. The remainder of the article is targeted at those that want to get decent matrix-multiplication performance and are familiar with concepts such as bank conflicts, warps, assembly code, vector operations and instruction latency.
The main reason why I wrote this article - and the code - is the poor performance of the clBlas library on NVIDIA GPUs. I worked on a project that required acceleration of code on an NVIDIA Tesla K40m GPU using OpenCL. Since its main component was a dense single-precision matrix-multiplication, I made a call to the SGEMM routine of clBlas. It turned out that clBlas is roughly a factor 5-6 slower (on my GPU) compared to its CUDA counterpart cuBLAS: clBlas does not get much more than 500 GFLOPS (out-of-the-box) or 700 GFLOPS (tuned), whereas the far superior cuBLAS reaches a little over 3 TFLOPS (~80% of the GPU's peak performance). This is shown in the image below, which also includes my best-case performance so far ("myGEMM").
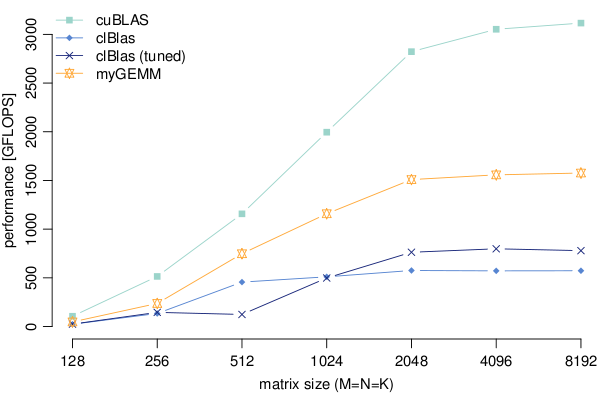
Like I said, we'll go over the optimisations step-by-step. And remember, they all come with OpenCL code, so please _do_ try this at home. Just a quick heads-up of what the steps are:
- Naive implementation
- Tiling in the local memory
- Increased work per thread
- Wider data-types (vectors)
- Transposed input matrix and rectangular tiles
- 2D register blocking
- Wider loads with register blocking
- CUDA and Kepler-specific optimisations
- Software pre-fetching
- Incomplete tiles and support for arbitrary matrix-sizes
Technical notes: All tests were performed on a Kepler SM 3.5 GPU, the Tesla K40m. The GPU was configured with ECC enabled. Version 6.5 of the CUDA toolkit was used (including OpenCL).