
Tutorial: OpenCL SGEMM tuning for Kepler
Note: the complete source-code is available at GitHub.Note2: a tuned OpenCL BLAS library based on this tutorial is now available at GitHub.
Note3: a WebGL2 demo of this tutorial is available at: https://www.ibiblio.org/e-notes/webgl/gpu/mul/sgemm.htm.
Performance on AMD GPUs
So, clBlas is not the best choice on NVIDIA GPUs. But then it must be great on AMD GPUs, right? We tested on an AMD FirePro W9100 and an AMD Radeon R9 280X, which have respectively 2816 and 2048 cores at 930MHz and 1150MHz. This translates to 5.2 TFLOPS (W9100) and 4.3 TFLOPS (R9 280X) single-precision peak, more than NVIDIA's K40m. But can we use those flops for matrix-multiplications?We first tested clBlas (out-of-the-box) on the AMD GPUs and saw that it produced the exact same OpenCL kernel as on NVIDIA's GPU. So there is neither foul play nor are there any device-specific optimisations or parameters. The R9 280X achieves 1857 GFLOPS (out-of-the-box) and 2546 GFLOPS (tuned) with clBlas. This is more than on the K40m, and the auto-tuning definitely adds something. But it does not match the cuBLAS performance.
NOTE: Results for the W9100 are temporarily removed and will be updated later once variations in execution-time are fixed.
We also tested all our own OpenCL kernels (tuned for the Tesla K40m). The results show that performance-portability is definitely not a feature of OpenCL: performance ranges from a couple of GFLOPS to over 1 TFLOPS (see below). Note that we had to adjust the work-group sizes of myGEMM1 and myGEMM2 to 16 by 16 because 32 by 32 was not supported.
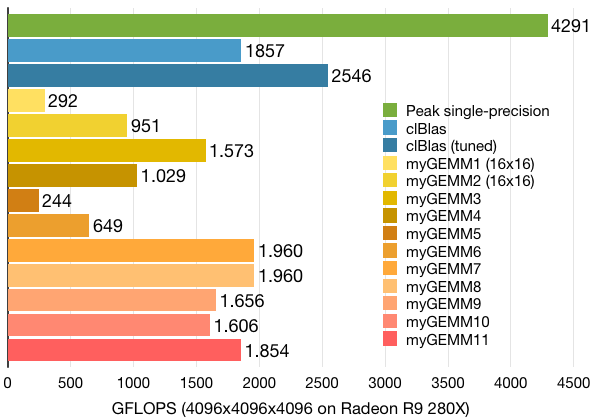
Investigation of these results is not something we will do here, we'll leave that up to you (yay, homework!). We note that there is other work on AMD GPUs which achieves decent results after tuning (see below).
Further reading:
- A Trip to Tahiti: Approaching a 5 TFlop SGEMM Using 3 AMD GPUs. R. Weber and G.D. Peterson. In: SAAHPC '12. IEEE.
- Performance Tuning of Matrix Multiplication in OpenCL on Different GPUs and CPUs. K. Matsumoto, N. Nakasato, S.G. Sedukhin. In: SC-Companion '12. IEEE.
- Implementing Level-3 BLAS Routines in OpenCL on Different Processing Units. K. Matsumoto, N. Nakasato, S.G. Sedukhin. In: TR 2014-001. University of Aizu, Japan.
Special thanks to StreamComputing for giving access to the FirePro W9100 GPU and to Mark Wijtvliet of the TU/e for giving access to the Radeon R9 280X GPU.